
The window for holding the absolute crown in frontier artificial intelligence is no longer measured in years, or even months. It is now measured in weeks. Today, Anthropic has thrown down the gauntlet by launching its latest flagship model, Claude Opus 4.8.
This is not merely another minor incremental benchmark update. It represents a fundamental architectural pivot, away from passive chatbot conversationalists and towards fully autonomous, self-correcting agents capable of orchestrating highly complex software engineering and professional tasks.
As developers and enterprises scramble to dissect the implications of this sudden release, one question dominates the technological landscape: Has Anthropic just preemptively neutralised OpenAI’s highly anticipated GPT-5?
1. The Agentic Leap: Orchestrating ‘Dynamic Workflows’
At the absolute core of the Opus 4.8 update is a groundbreaking research preview feature dubbed Dynamic Workflows, integrated directly into the new Claude Code terminal interface.
Historically, large language models have operated on linear instruction structures. You provide a prompt; the model delivers a response. If a task is too large, the system breaks or halts. Opus 4.8 completely rewrites this manual operating model.
When faced with massive, multi-step engineering problems, Claude Opus 4.8 can:
- Autonomously blueprint a strategy before writing a single line of code.
- Spawn and coordinate hundreds of parallel sub-agents within a single session to handle concurrent engineering processes.
- Migrate complex codebases spanning hundreds of thousands of lines of code.
- Run existing test suites, spot failure logs, rewrite its own code, and re-test until it achieves a flawless compile.
“On our Super-Agent benchmark, Claude Opus 4.8 is currently the only model on the market to complete every single complex enterprise test case end-to-end,” reports Kay Zhu, Co-Founder and CTO of emerging agent developer platform CursorBench. “It beats prior Opus architectures and GPT-5.5 at absolute parity on operational costs.”

2. The Power of Cognitive Pause: Introducing ‘Effort Control’
In addition to back-end agentic updates, Anthropic is rolling out a new user interface paradigm across Claude.ai and Cowork: Effort Control.
Positioned directly alongside the model selector, this new slider allows users to manually dictate the computational depth, and reasoning latency, allocated to any given task.
Editorial Note: This is Anthropic’s direct structural counter-offensive to OpenAI’s o-series reasoning models. Instead of forcing users into a one-size-fits-all response speed, Effort Control allows developers to actively ration their compute budgets.
For simple tasks, sliding to “Low Effort” activates a newly optimised Fast Mode that delivers rapid replies at a fraction of the cost. However, pushing the slider to “Maximum Autonomy” triggers deep-reasoning layers. The model pauses, deliberates, queries its own sub-agents, and systematically verifies its own output before rendering.
This “cognitive pause” yields staggering results in alignment. Anthropic’s internal evaluations reveal that Claude Opus 4.8 is four times less likely to leave silent, critical bugs in code compared to its predecessor, Opus 4.7. Rather than trying to “please” the user with a fast but flawed answer, Opus 4.8 actively flags uncertainties and pushes back when an initial engineering plan is structurally unsound.
3. Shifting the Economics of the AI Arms War
While raw intelligence is paramount, the ultimate bottleneck to widespread corporate agent adoption is cost. Here, Anthropic has made a highly strategic economic manoeuvre.
Although standard API pricing remains flat at $5 per million input tokens and $25 per million output tokens, the upgraded Fast Mode is now 2.5× faster and 3× cheaper than any previous fast-tracking options.
By slashing the cost of rapid, iterative agent actions, Anthropic is deliberately targeting the developer ecosystems that build micro-agents. When an autonomous system needs to make thousands of calls a day to monitor logs, manage transactions, or translate databases, a 3× cost reduction is not just a saving, it is a complete catalyst for a new class of viable consumer startups.
4. Unrivalled Honesty and the Safety Framework
One of the most persistent complaints amongst enterprise clients utilising frontier models is “silent hallucination”, instances where an AI confidently asserts a false claim or writes faulty code without warning the user.
With Opus 4.8, Anthropic has prioritised “honesty” as a core performance metric. Early testers report that the model has developed an acute sense of its own limitations. If it cannot verify a file pathway or feels a logic branch is weak, it explicitly flags the uncertainty to the developer.
This structural safety aligns Opus 4.8 with Anthropic’s highly secretive Mythos-class safety architecture. Anthropic has dropped strong hints that its next-generation Mythos-class models, designed from the ground up for extreme safety, zero-hallucination compliance, and massive scaling, will begin rolling out to enterprise partners in the coming weeks. Opus 4.8 serves as a robust bridge to that next paradigm, offering similar alignment characteristics to the restricted Mythos Preview.
5. The Verdict: Is it the GPT-5 Killer?
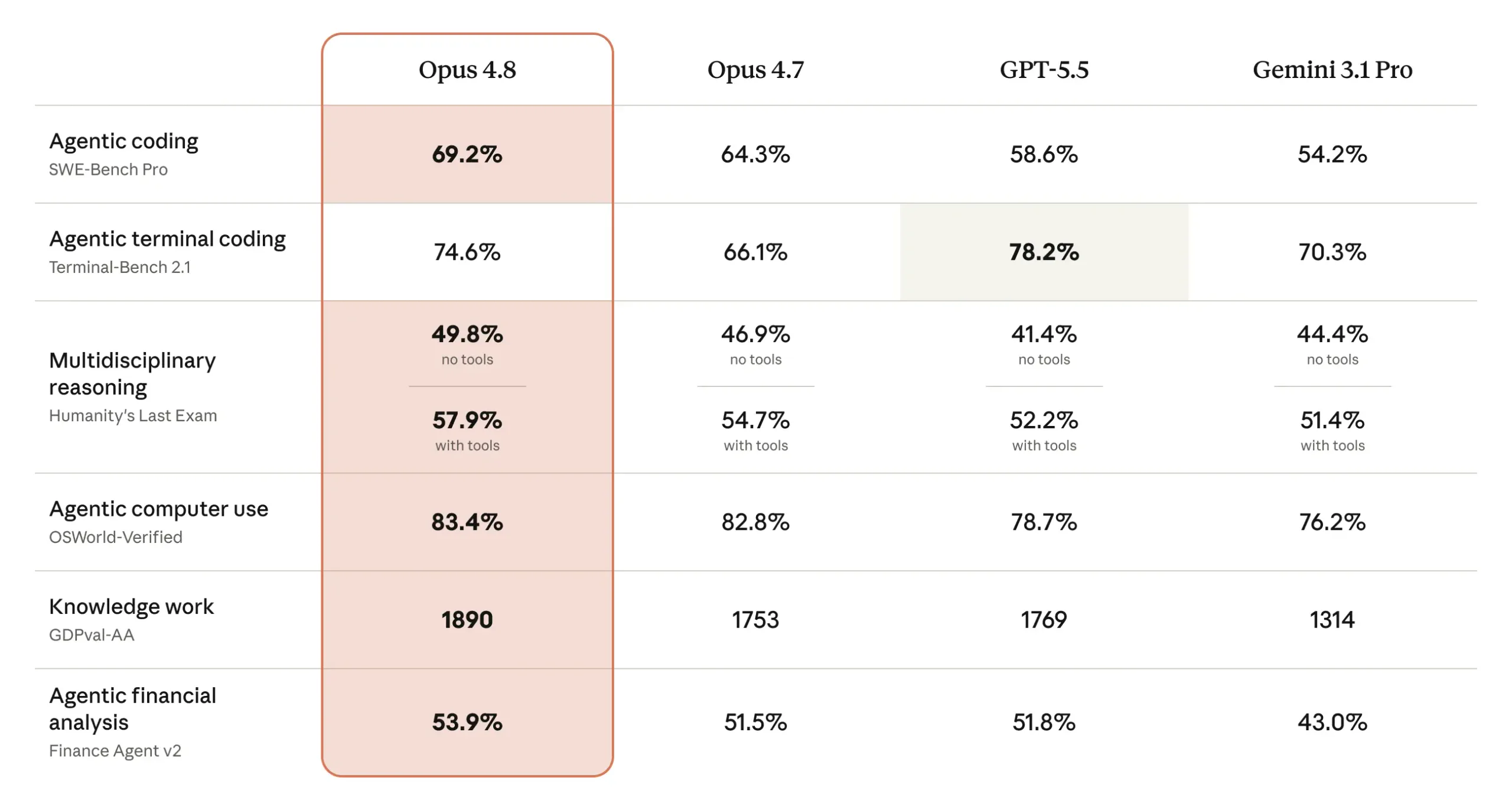
When we look closely at the empirical benchmarks, the narrative becomes clear. Claude Opus 4.8 does not just match the current landscape; it actively outpaces it in practical, agentic execution.
Its agentic coding score has jumped from 64.3% to 69.2%, while tool-based multidisciplinary reasoning has scaled up to 57.9%. Perhaps most impressively, in agentic computer use, it has reached a commanding 83.4% reliability rating.
By combining extreme multi-agent autonomy with cost-optimised fast modes and manual effort controls, Anthropic has moved beyond the “chatbot paradigm”. If GPT-5 arrives merely as a larger, more verbose conversational partner, it will struggle to compete with the sheer workspace utility of Claude Opus 4.8.
For modern enterprises, the choice is no longer about who has the cleverest chat interface. It is about who can run your engineering pipeline autonomously while you sleep. And right now, Anthropic is holding all the cards.